

2023年7月10日生成式人工智能新规靴子落地,国家六部门发布《生成式人工智能服务管理暂行办法》(“《暂行办法》”)正式文件,就生成式人工智能的发展与监管思路确定了市场预期。制定者从善如流,广泛吸收修改建议后,在《暂行办法》中根据市场实践对调整对象与适用范围、鼓励发展政策与监管原则、提供者与使用者义务、实名制、内容合规与个人信息保护、监管措施等六个方面较《生成式人工智能服务管理办法(征求意见稿)》(“《征求意见稿》”)作出了实质性修改。《暂行办法》8月15日的实施日期在即,本文从《暂行办法》与《征求意见稿》对比的角度切入,对《暂行办法》修订的亮点进行简要的介绍,并尝试对相关企业的合规制度完善提供粗浅的建议,以供参考。
一、 征求意见与新规对比
(一) 调整对象与适用范围

综上,可以就《暂行办法》的调整对象得出如下结论:向中国境内公众提供生成式AI及相关衍生服务,以及在中国境内使用生成式AI及相关衍生服务的,则适用《暂行办法》中的规定。但如果是有关机构内部研发、应用生成式AI及相关衍生服务而未向不特定多数人提供的,则不适用《暂行办法》,至于该等生成式AI是否来源于境外(典型如ChatGPT)则在所不问。《暂行办法》从调整对象中排除了对于生成式人工智能(“AI”)产品研发行为的适用,并专设第三款明确了针对生成式AI的研发行为的边界(即自行研发、应用,不向境内公众提供)。此外,在立法语言上,调整对象的重心从调整“研发、利用” 生成式AI的“行为”向利用生成式人工智能技术提供的“服务”转变,从语义逻辑上囊括进了使用者使用该等服务的行为,这一调整在第四条(见下)中由“提供”修改为“提供和使用”也可得到印证。
根据上述理解,《暂行办法》至少适用于以下典型场景:
1. 某公司甲开发生成式AI向中国境内公众提供(不论是否盈利);
2. 位于中国境内的个人或者组织乙使用甲所开发的生成式AI;
3. 甲搭建接口接入境外的生成式AI(如ChatGPT)并制作衍生的问答服务产品向公众提供(不论是否盈利);
4. 位于境外的OpenAI向境内公众提供ChatGPT及可能的衍生服务;
同时,《暂行办法》至少不适用于以下典型场景:
1. 甲自研生成式AI,未向中国境内公众提供;
2. 甲自研生成式AI成功后,仅为提高本公司的生产效率,未向中国境内提供,仅在公司内部使用;
3. 甲为研发新的生成式AI而搭建接口使用ChatGPT等境外生成式AI。
(二) 鼓励发展政策与监管原则
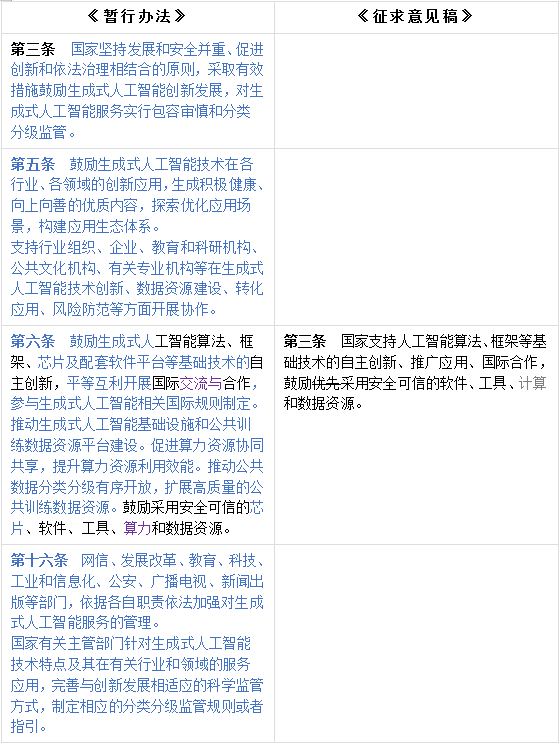
就分类分级监管原则而言,虽尚无明确的条文出台,但是结合目前理论与实务的关注重心来看,效法欧盟的《人工智能法案》(Artificial Intelligence Act)收获的呼声最高。在《征求意见稿》的基础上,《暂行办法》进一步扩充了整体层面支持生成式AI技术发展的思路与方向,没有设立行为模式或者法律后果。但除去鼓励支持生成式人工智能发展的政策部分,需要留意的是为各主管部门确定了一致的监管原则:“包容审慎监管”和“分类分级监管”。包容审慎监管原则在《暂行办法》自身的条文设置上已经可以窥见一斑,但是分类分级监管原则在《暂行办法》中没有具体的规则条文与之呼应,第三条与第十六条一并将细化与贯彻分类分级监管原则的任务分配给了各相关的职能部门。
《人工智能法案》草案中将人工智能系统的风险划分为“低或轻微风险(Low or Minimum Risk)”、“高风险(High Risk)”、“有限风险(Limited Risk)”及“不可接受风险(Unacceptable Risk)”。被划分为“低或轻微风险”的人工智能系统,可不列入监管范围;被划定“有限风险”的人工智能系统,则被要求必须遵循透明度原则,评估和减少可能的风险,并在欧盟市场发布前应在欧盟数据库中进行注册;对于“高风险”的人工智能系统,开发者应采取严格的监管措施,并在投放市场之前以及在产品运营的整个生命周期内接受安全评估;至于“不可接受风险”的人工智能系统,则被禁止进入市场[1]。
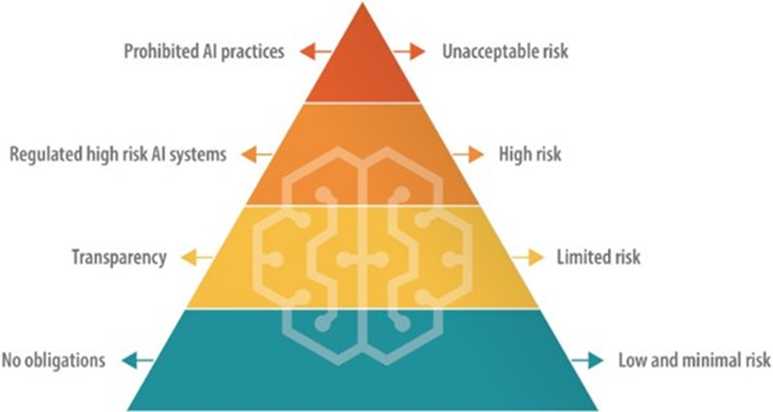
图1《人工智能法案》草案下的监管框架示意图[2]
目光回到我国来看,人工智能法草案已列入2023年国务院立法工作计划提请全国人大审议[3],分类分级监管的立法思路是沿袭欧盟在法案中定性定调,还是各相关部门直接在《暂行办法》的基础上进行细化规定先投石问路,再由人工智能法来总结立法经验后跟上,短期之内似乎仍不够明晰,对此仍然需要及时跟进关注立法动态进行观察。
(三) 提供者与使用者义务

第四条的修改需要关注的除了前文所述的使用者加入到规制主体与提供者并行之外,还需要关注的是《暂行办法》的第(五)项对《征求意见稿》第(四)项的修改。《征求意见稿》要求提供者做到生成式AI生成的内容“真实准确”,并“采取措施防止生成虚假信息”。但是从技术角度而言,这确实向提供者提出了难以完成的任务,生成式AI的底层概念之一是马尔可夫链(Markov Chain)[4],生成式AI在马尔可夫链的算法逻辑上,结合巨量数据根据第n-1个词汇预测产生第n个词汇,而不是简单的通过在线检索和查阅来得出结论,这也正是生成式AI的“创造性”所在。基于马尔可夫链模型,生成式AI难以保证生成内容的真实准确。制定者在广泛听取了社会意见后,从善如流,在《暂行办法》中即刻将提供者对于生成内容的真实准确性的保证要求删去,替之以“采取有效措施……提高…..准确性和可靠性”的指引性规范,这也更加符合产业的实际特点。
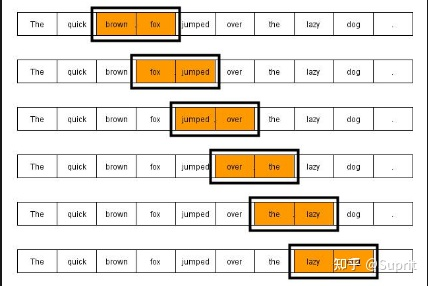
图2马尔可夫链模型“听懂”人类语言的模式示意图[5]
(四) 取消实名制

《暂行办法》中删去了《征求意见稿》第九条关于使用者实名制的要求。这虽然与当下治理网络环境的整体要求相一致,但是在当前境内大量生成式AI来自于境外的大背景下,我境内执法部门难以对境外提供者提出实名要求,“长臂管辖”的执法难度陡增。这也同时导致该等合规成本实际上只得由境内提供者来承担,但是从产业的实际发展情况来看,境内的生成式AI相较于境外的生成式AI而言仍处于步履蹒跚的阶段,这一阶段提出落实实名制的要求可能对于发展境内生成式AI而言并不适宜。也许是考虑到这一实际,制定者便删去了《暂行办法》中的实名要求。不过结合当前互联网治理的整体背景和趋势来看,未来对于生成式AI提出实名制要求的可能性也是非常高的。
(五) 内容合规与个人信息保护

此外需要留意的是,《暂行办法》删去了《征求意见稿》第十五条对提供者3个月通过模型优化训练的严格时限要求,代之以及时整改义务,以及在完成整改后向有关主管部门的报告义务。在义务分配的格局上,《暂行办法》给使用者分配了不违反法律规定和不侵害他人合法权益等消极义务,另一方面对于提供者而言,除了前述的消极义务外,《暂行办法》在《征求意见稿》的规定之上更加明确了提供者对于使用者的个人信息保护义务、对于生成式AI内出现的违法内容的处理责任以及健全投诉举报机制的义务要求。这些要求在《征求意见稿》已经做了原则性要求,在《暂行办法》层面则提出了更加具体可执行的要求。在2023年8月15日《暂行办法》实施之日前,提供者应当就如何履行《暂行办法》的提出的合规要求作出安排。
(六) 监管措施

另外于《暂行办法》第二十一条而言,删去了《征求意见稿》第二十条规定的罚则,而替之以警告、通报批评、责令限期改正以及责令暂停提供相关服务。这一修改无疑是“包容审慎”监管原则的最佳注脚。如果没有违法其他的法律法规,在《暂行办法》的格局下,最重的处理是责令停止服务,转向宽松的处罚力度亦体现了制定者对于发展生成式AI的支持态度。《征求意见稿》的原有安排下,对于境外提供者向境内提供生成式AI已有管控依据的供给,但是在当前境外提供者的生成式AI占据主流的市场格局下,单纯按照《征求意见稿》的第二十条追究责任似乎容易导致这一责任沦为具文。对此《暂行办法》新增第二十条,为监管部门对于境外提供者向进行提供生成式AI提供了更加灵活的监管手段和空间。但是当前规定给足监管部门监管的灵活空间的反面,就是造成了市场预期的不确定性。具体监管措施的缺乏带来的宽泛行政裁量空间不利于产业发展,但可能也是当前监管的无奈之举。就此而言,仍需要密切观察对于境外提供者提供的生成式AI具体的监管措施,以建立可控的市场预期。
二、 对于企业的合规建议
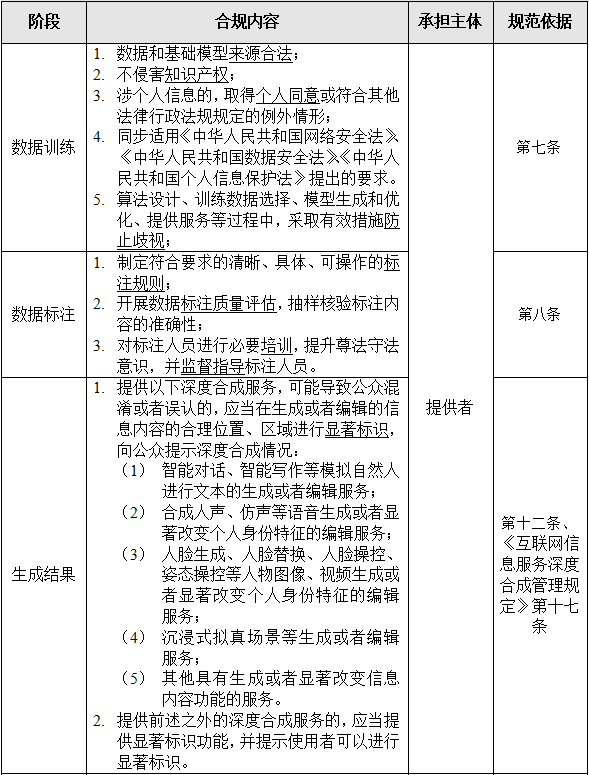
基于《暂行办法》,我们建议相关企业可以从如下方面考量合规制度的建设,但以下建议仍不构成任何正式的法律意见或者建议,具体如何设计合规制度,仍需要结合具体情况咨询您的律师或法律顾问。


[1] Briefing: Artificial Intelligence Act, European Parliamentary Research Service,https://www.europarl.europa.eu/RegData/etudes/BRIE/2021/698792/EPRS_BRI(2021)698792_EN.pdf.
[2] Id.
[3] 科技部:人工智能法草案已列入国务院2023年立法工作计划. 澎湃新闻.https://www.thepaper.cn/newsDetail_forward_23751642
[4] https://zhuanlan.zhihu.com/p/448575579
[5] Id.
附:
1. 国家互联网信息办公室关于《生成式人工智能服务管理办法(征求意见稿)》公开征求意见的通知
http://www.cac.gov.cn/2023-04/11/c_1682854275475410.htm
2. 《生成式人工智能服务管理暂行办法》
https://www.gov.cn/zhengce/zhengceku/202307/content_6891752.htm

